常见SEO阿里云服务器升级硬盘AI服务器部署方案:从底层硬件到算力集群的完整解析
发布时间:2025-12-20 01:41:22 作者:熊猫主机教程网
简介 云服务器 做代理服务器 2025-09-14 08:00·硬科技赛道首席拆解官 作品声明:个人观点、仅供参考 AI服务器部署方案:从底层硬件到算力集群的完整解析 导语 在AI大模型时代,服务器已经不再是传统意义上的计算盒子,而是支撑整个智能产业的算力发动机。无论是ChatGPT这样的生成式AI,还是自动驾驶、
云服务器 做代理服务器

2025-09-14 08:00·硬科技赛道首席拆解官
作品声明:个人观点、仅供参考
AI服务器部署方案:从底层硬件到算力集群的完整解析
导语
在AI大模型时代,服务器已经不再是传统意义上的计算盒子,而是支撑整个智能产业的算力发动机。无论是ChatGPT这样的生成式AI,还是自动驾驶、智能工厂、金融风控,背后都依赖于庞大的AI服务器集群。本文将系统梳理AI服务器的部署方案,从硬件选择、网络架构、虚拟化与容器,到算力调度与运维安全,帮助读者理解一个完整的AI服务器部署全景。
一、为什么AI服务器如此重要?
1. AI算力需求爆发
大模型训练需要数千张GPU卡并行运算。推理服务则要求低延迟、高并发。云计算厂商、互联网公司、科研机构纷纷加码AI服务器集群。2. 与传统服务器的区别
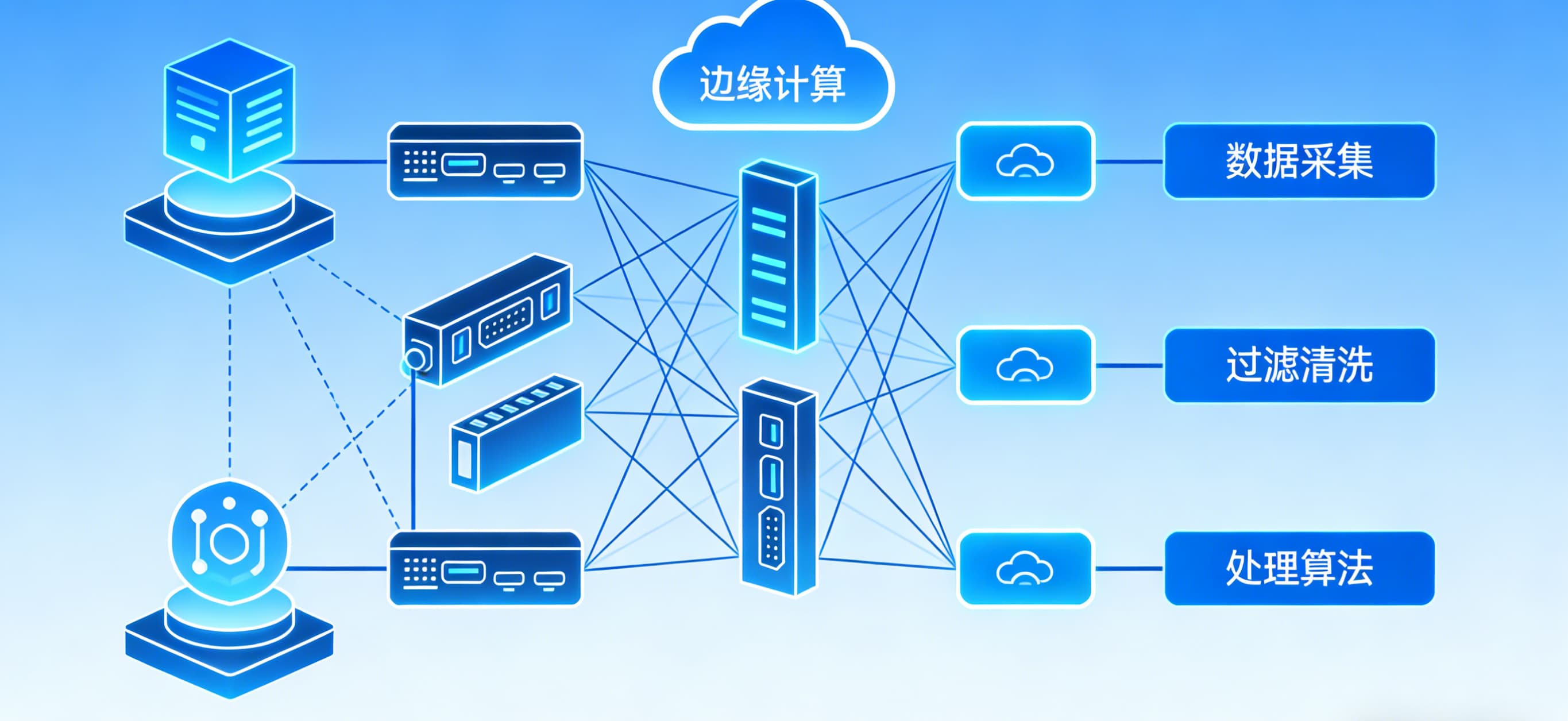
CPU主导 → GPU/加速卡主导。内存需求:AI训练往往需要TB级内存。网络:从千兆以太网升级到400G甚至800G高速互联。存储:NVMe SSD、分布式存储,满足PB级数据吞吐。二、AI服务器的核心硬件选择
1. 处理器(CPU & GPU)
CPU:仍然负责通用计算与调度,推荐选择多核高主频产品(如Intel Xeon、AMD EPYC)。GPU/加速卡:NVIDIA H100、A100是行业标配;国产方案如华为昇腾、寒武纪MLU也在快速发展。未来趋势:异构计算(CPU+GPU+FPGA+专用AI芯片)。2. 内存与高速缓存
单机内存从256GB到2TB不等。HBM(高带宽内存)成为AI GPU的核心。NUMA架构需要精细化调优。3. 网络与互联
Infiniband HDR/NDR,支持RDMA(远程直接内存访问)。400G以太网成为主流。光模块、交换机的性能直接决定集群训练速度。4. 存储系统
高速NVMe SSD存储训练样本。分布式文件系统(Ceph、BeeGFS、Lustre)。数据冷存储(HDD+对象存储)降低成本。三、AI服务器的基础架构设计
1. 单机到集群
单机适合推理、小规模训练。大规模训练需要成百上千台服务器组成集群。2. 集群架构
计算节点:搭载GPU的高性能服务器。管理节点:负责调度、监控、认证。存储节点:提供共享文件系统。网络节点:承载高速互联。3. 数据中心环境
机房电力与散热成为关键瓶颈。液冷技术逐渐取代风冷。PUE(电能使用效率)是IDC核心指标。四、虚拟化与容器化方案
1. 虚拟化
传统VMware/KVM方案适合业务隔离,但开销大。2. 容器化
Kubernetes(K8s)成为AI集群标准。GPU Operator插件可自动化部署GPU驱动与CUDA环境。容器化推理可快速扩缩容。3. 混合方案
训练采用裸金属 + GPU直通。推理采用K8s容器化,提高资源利用率。五、算力调度与集群管理
1. 作业调度
华为云服务器无法访问
Slurm:科研领域标准。Kubernetes + Kubeflow:企业常用AI工作流平台。Ray:大规模分布式AI计算框架。2. 资源管理
GPU隔离与分配。多租户调度与配额。动态弹性伸缩。3. 监控与可观测性
Prometheus + Grafana:资源监控。Datadog、ELK:日志与链路追踪。AIOps:自动告警与预测。六、AI服务器部署的安全与合规
1. 网络安全
防火墙 + 零信任架构。内外网分离,GPU节点只跑训练,不直连公网。2. 数据安全
数据加密存储。访问控制(RBAC)。日志审计。3. 合规与绿色计算
符合各国数据合规要求(如GDPR、数据出境管控)。碳中和与绿色节能成为IDC新要求。七、典型部署场景案例
1. 云服务商(阿里云、AWS、GCP)
公有云AI集群,弹性资源池,支持大模型训练。适合中小企业快速试错。2. 科研机构
高性能计算(HPC)集群。重点是算力+带宽。3. 企业自建数据中心
银行、能源、电信行业倾向自建,保障数据安全。投资额从千万到数十亿人民币不等。八、部署流程与实施步骤
步骤1:需求评估
模型规模、训练周期、并发推理量。成本预算与能耗限制。步骤2:硬件选型
GPU数量、网络拓扑、存储容量。步骤3:机房环境准备
电力、散热、机柜布局。步骤4:操作系统与驱动安装
Linux + CUDA/cuDNN + NCCL。步骤5:容器与调度系统部署
Kubernetes + GPU Operator。步骤6:AI框架适配
TensorFlow、PyTorch、MindSpore。步骤7:运维与监控
日常监控、弹性调度、AIOps。九、未来趋势与展望
阿里云服务器升级系统
国产化替代:国产GPU、AI芯片、网络设备快速发展。液冷技术普及:解决功耗与散热难题。AI+大数据一体化平台:训练、推理、数据治理一站式。边缘AI服务器:5G+边缘计算结合,服务自动驾驶、工业IoT。结语
AI服务器的部署不仅是硬件堆叠,更是系统工程。它涉及底层芯片、操作系统、虚拟化、集群管理、数据安全、绿色节能等全链条。对于企业来说,部署方案的科学性将直接决定AI应用的落地效率与成本效益。在未来三到五年,谁能在算力布局上抢占先机,谁就能在AI产业的浪潮中站稳脚跟。
互动收尾:你觉得未来AI服务器的瓶颈是在GPU供给,还是在数据中心能耗?欢迎留言讨论
阿里云服务器维护教程
推荐阅读
- 阿里云服务器好卡新手也能轻松上手!轻松玩转多多云手机 2025-12-20 03:42:22
- 艾云 服务器手机连监控不用找师傅!5步轻松搞定,新手也能10分钟上手不踩坑 2025-12-20 03:32:15
- 阿里云服务器怎么挂机阿里云服务中断?数据中心冷却如何保证设施24小时运行 2025-12-20 03:22:13
- 阿里云学生服务器教程国产虚拟化软件评估必看:16家医院VMware替代实践合集 2025-12-20 03:12:04
- 阿里云服务器5m带宽如何制作宠物医院公司网站,宠物店网站搭建全攻略教程 2025-12-20 03:02:01