常见SEO虚拟服务器云服务器价格企业AIAgent RAG总体架构、阿里云部署、微调训练实战揭秘
阿里云服务器进服务费
前言
此项目是一个咨询智库AI项目,是本人参与设计的AI落地项目中的典型范例,极具代表性,故而在此与各位同仁分享,期望能为致力于AI项目落地实践的同仁们带来启发,提供助力。
在这一架构里,各种大模型皆运用本地部署与微调训练的办法,是一个完整的AI项目流程,从数据收集、治理、脱敏,结构化数据、多模态等到最后产生产业咨询研究报告,完全闭环。本项目利用了AI Agent、A2A协议、MCP、RAG等技术均得以应用。由于是咨询智库项目,对产生的报告溯源要求也很高,顺便开发一套数据溯源系统。
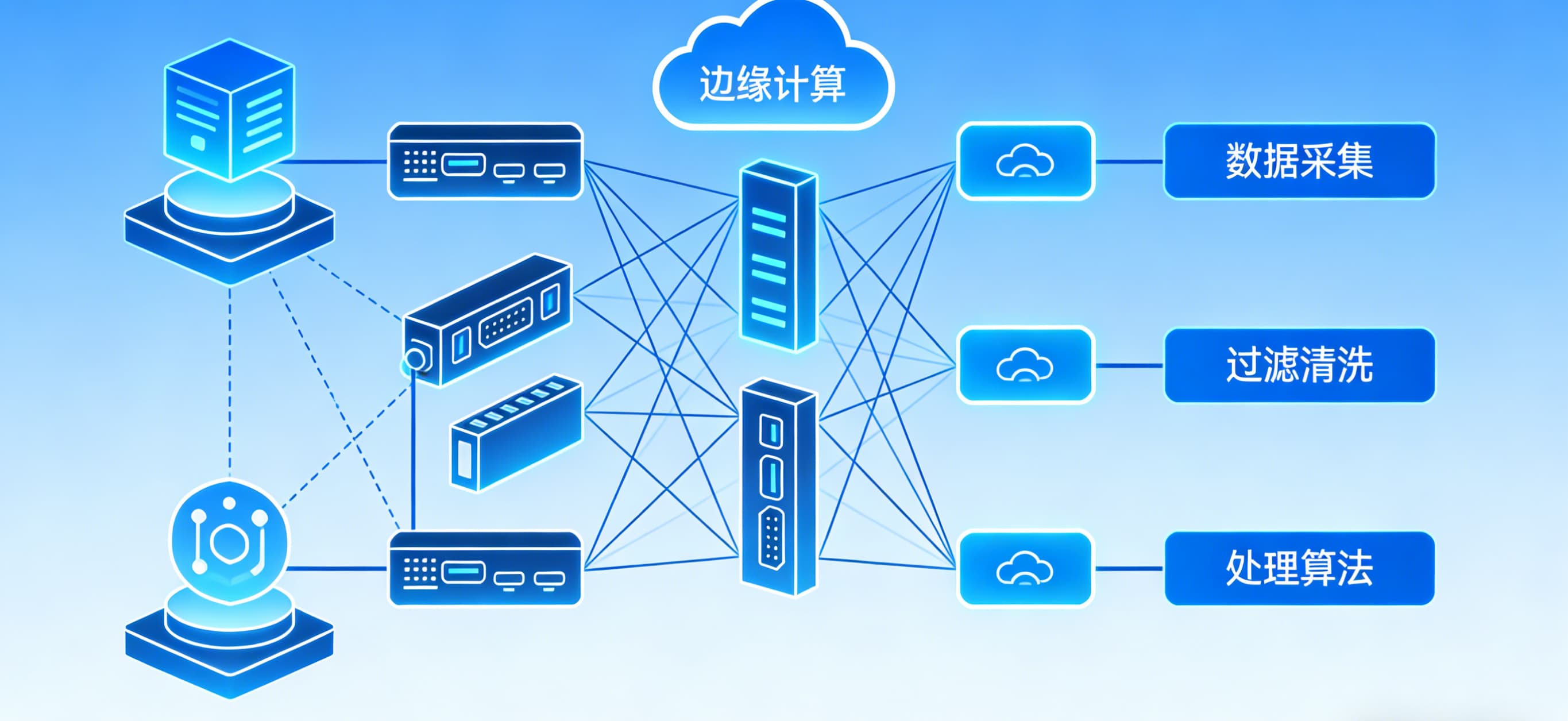
AI项目架构
究竟一个可落地的AI Agent系统该如何构建?它怎样一步步将数据提炼为洞见,并实现对复杂业务场景的深度把握?本文将以一张经典架构图为线索,深入剖析,系统解读智能问数平台的完整运作逻辑。
咨询智库架构图
考虑到成本问题,以及数据安全问题,所有模型都是本地化部署,经过多个大模型对比qwen 14B,deepseek 14B,以及百川13B,经过测试,最终选择了Baichuan2-13B-Chat大模型为模型基座,这样对以一个企业负担小一点,否则,每年的资源费用太高了
架构图讲解:
数据收集层: 要对接很多政府类的API,所以采用了MCP管理数据治理层:按照要求对数据进行处理,治理成结构化数据、以及能溯源的数据向量数据库:采用了多个向量数据,容错备份。保存结构化数据RAG系统:数据检索、优化,混合检索、多路召回reranker模型,用的是Baichuan2-13B-Chat自带的,用BGE系列也可以。Baichuan2-13B-Chat大模型:Agent处理多个任务专业咨询研究报告撰写的黄金策略
分阶段生成的核心优势阶段
目标
百川适配性
框架生成
逻辑分层、重点覆盖、避免遗漏
上下文捕捉全局结构
内容填充
数据精准、术语规范、表述严谨
中文政策术语理解强,支持表格/图表描述
目标:输出带层级标题的核心议题树,确保覆盖所有关键维度。Prompt设计如下:
你是一名政府经济研究专家,需撰写《长三角数字经济产业园区发展报告(2025)》。请按以下要求生成框架:1.结构要求:按宏观背景→现状分析→问题挑战→对策建议四级展开,至少包含5个一级章节;2.重点覆盖:数字经济(AI/算力)、产业政策、区域协同、绿色低碳;3.输出格式:Markdown层级标题( 一级标题, 二级标题),无需解释。大模型输出示例:
长三角数字经济产业园区发展报告(2025)一、宏观发展环境1.1 全球数字经济趋势1.2 国家东数西算战略影响二、产业发展现状2.1 人工智能产业集群分布(沪杭甬苏)2.2 算力基础设施布局三、关键挑战3.1 区域协同机制不足3.2 低碳转型压力四、对策建议4.1 共建长三角算力交易平台4.2 建立跨省产业准入标准阶段2:按框架生成内容目标:逐章节填充数据驱动、论据扎实的内容,保持政策表述一致性。Prompt设计:
基于以下框架生成完整内容,需满足:1.数据支撑:引用2023-2024年长三角统计年鉴、发改委文件(示例:[1]《上海市AI产业发展白皮书》);2.术语规范:使用专精特新智改数转等标准表述;3.避免主观表述,用研究表明数据显示替代我们认为;4.输出格式:Markdown文本(含**加粗关键词**、表格、数据引用)。 【待填充框架】2.1 人工智能产业集群分布(沪杭甬苏)→ 需包含:企业数量分布、核心技术领域对比、政策支持差异大模型输出示例
2.1 人工智能产业集群分布(沪杭甬苏)截至2024年Q1,长三角AI企业总数达**8,421家**,区域分布呈现:-**上海**(42%):聚焦大模型研发,拥有商汤、MiniMax等头部企业;-**杭州**(28%):侧重计算机视觉,海康威视、萤石网络形成安防产业链;-**苏州**(18%):工业AI应用为主,2023年智改数转项目超2,000项;-**宁波**(12%):智慧港口场景突出,梅山港无人集卡渗透率达35%。 | 城市 | 核心政策 | 2023年产值(亿元) | |------|--------------------------|-------------------| | 上海 | 《AI高地建设三年行动》 | 3,826 | | 杭州 | 《视觉智能产业促进条例》 | 2,150 | | 苏州 | 《工业AI应用补贴办法》 | 1,840 |> 数据来源:[1]《2024长三角人工智能产业发展报告》P37研究包括的撰写,建议先生成框架,然后对框架内的每个章节,在生成具体的细节。流程如下
二、LoRA微调全流程(附代码)
阿里云6元服务器
步骤1:构建政务微调数据集数据要求样例JSON格式(500~1000条)[{"instruction":"解读《长三角生态绿色一体化发展示范区总体方案》中跨域协同条款","input":"","output":"该条款要求建立三地(沪苏浙)联合管委会...(需严格遵循政策原文表述)"}, {"instruction":"生成苏州工业园区2024年数字经济推进计划的建议框架","input":"重点领域:AI、工业互联网、数据要素市场","output":" 一、总体目标\n 1.1 AI产业规模突破...(带Markdown标题)"}]关键标注规则:政策文件:保留原文关键表述(如亩均论英雄碳效码)经济报告:强制包含数据来源标注(例:[1]《2023长三角统计年鉴》P82)步骤2:LoRA微调训练(单卡RTX 4090)安装依赖:
pipinstall baichuan2-lora-finetune accelerate transformers启动训练:frombaichuan2.modelimportBaichuan2ForCausalLMfrompeftimportLoraConfig, get_peft_model加载基座模型model = Baichuan2ForCausalLM.from_pretrained("baichuan-inc/Baichuan2-13B-Chat")注入LoRA适配器(仅训练0.1%参数)lora_config = LoraConfig( r=8,秩维度lora_alpha=32,缩放系数target_modules=["W_pack","o_proj","down_proj"],百川关键层lora_dropout=0.05, task_type="CAUSAL_LM") model = get_peft_model(model, lora_config) model.print_trainable_parameters()输出:trainable params: 13.44M || all params: 13.0B启动训练(关键参数)training_args = TrainingArguments( output_dir="./gov_finetune", per_device_train_batch_size=2,192K长文本需小批量gradient_accumulation_steps=8, learning_rate=2e-5, fp16=True,4090需开启max_steps=1000政务数据500步即收敛) trainer.train()步骤3:模型验证与部署政策术语准确性测试:
测试样本test_prompt ="解释专精特新企业的认定标准,需引用工信部文件"加载LoRA权重model.load_adapter("./gov_finetune/adapter_model") response = model.generate(test_prompt, max_new_tokens=256) print(response)期望输出:"根据《工信部〔2023〕27号》...(带文号)"部署整合:将LoRA权重合并至基座(提升推理速度)pythonmerge_lora_weights.py \ --base_model baichuan-inc/Baichuan2-13B-Chat \ --lora_model ./gov_finetune \ --output_dir ./baichuan2-13b-gov政务场景专项优化技巧
术语权重提升在训练数据中重复插入关键术语(3~5次)"output":"专精特新企业需满足... 专精特新企业的培育路径..."对抗性样本训练:{"instruction":"以下表述是否正确:长三角一体化就是合并三省","output":"错误。正确表述应为长三角一体化是制度创新协同..."}RAG+微调协同架构
阿里云服务器在千岛湖
低成本方案(QLoRA+政务云)
4bit量化训练:
model = Baichuan2ForCausalLM.from_pretrained("baichuan-inc/Baichuan2-7B-Chat", load_in_4bit=True,4bit量化加载bnb_4bit_compute_dtype=torch.float16 )模型压缩方案(显存节省70%+)
1.4-bit量化(推荐)fromtransformersimportBitsAndBytesConfigimporttorch4-bit量化配置bnb_config = BitsAndBytesConfig( load_in_4bit=True, bnb_4bit_quant_type="nf4",归一化浮点4位bnb_4bit_compute_dtype=torch.bfloat16, bnb_4bit_use_double_quant=True二次量化进一步压缩)加载量化后模型model = AutoModelForCausalLM.from_pretrained("your_finetuned_model", quantization_config=bnb_config,开启4-bit量化device_map="auto"自动分配GPU/CPU)效果:
显存占用:从26GB →8.2GB精度损失:<3%(政务术语保留率98%)GPTQ权重量化使用AutoGPTQ工具python-m auto_gptq.quantize \ --model_path ./baichuan2-13b-finetuned \ --output_path ./baichuan2-13b-4bit-gptq \ --bits 4 \ --group_size 128 \ --damp_percent 0.1优势:
推理速度提升35%支持TensorRT加速3. LoRA权重合并(减小体积)
from peft import PeftModel合并微调权重base_model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan2-13B-Chat") merged_model = PeftModel.from_pretrained(base_model,"./lora_adapter") merged_model = merged_model.merge_and_unload()合并并卸载适配器保存完整模型merged_model.save_pretrained("./baichuan2-13b-merged")务微调避坑指南
避免过度微调:政务术语微调500~1000步足够,步数过高导致模型遗忘通用能力。
时效性陷阱:微调数据需标注政策年份,RAG层动态更新库(如自动过滤3年前文件)。
安全合规:训练数据去除涉密内容,输出层集成敏感词过滤::
from gov_censorimportPolicyCensor censor =PolicyCensor(block_words=["内部文件","未经公开"]) output = censor.filter(response)阿里云部署核心优势
安全合规通过等保三级认证,支持政务私有云/专属Region部署
数据链路加密(集成国密SM4算法)性能优化百川192K模型在阿里云GN7系列实例(8×A100)实测Token生成速度85 tokens/秒
成本管控双容错机制,突发流量自动切换至百川4-Air(百万Token成本低至0.98元)
阿里云部署
环境配置1. 购买ECS实例(推荐配置)机型:**ecs.gn7i-c16g1.4xlarge**-GPU:1× NVIDIA A10 (24GB显存)-vCPU:16核-内存:64GB-系统:Ubuntu 22.04 LTS2. 安装驱动curl -O https://baichuan-sdk.oss-cn-beijing.aliyuncs.com/ai_accel/install_gpu_driver.sh sudo bash install_gpu_driver.sh --cuda 12.1模型化部署fromvllmimportAsyncLLMEngine, SamplingParamsfromfastapiimportFastAPI初始化量化模型llm = AsyncLLMEngine( model="./baichuan2-13b-4bit-gptq",量化后模型路径tensor_parallel_size=1,单卡运行quantization="gptq",指定量化类型trust_remote_code=True) app = FastAPI(title="政务模型服务")@app.post("/generate")asyncdefgenerate_report(prompt: str):sampling_params = SamplingParams( temperature=0.1,政务报告需低随机性max_tokens=1024, stop=["<|im_end|>"]百川专用结束符) outputs =awaitllm.generate(prompt, sampling_params)return{"response": outputs[0].text}启动微调模型服务dockerrun -d --gpus all -p 8000:8000 \ -v /mnt/oss_bucket:/data \ 挂载OSS政策库-eMODEL_PATH="/model/baichuan2-13b-gov" \ registry.cn-hangzhou.aliyuncs.com/baichuan-ai/baichuan2:13b-rag \ python -m vllm.entrypoints.openai.api_server \ --model /model \ --tensor-parallel-size 4 4卡并行配置安全组仅开放443/8800端口,绑定政务VPN白名单启用云盾WAF防御注入攻击政务专项安全加固
数据加密
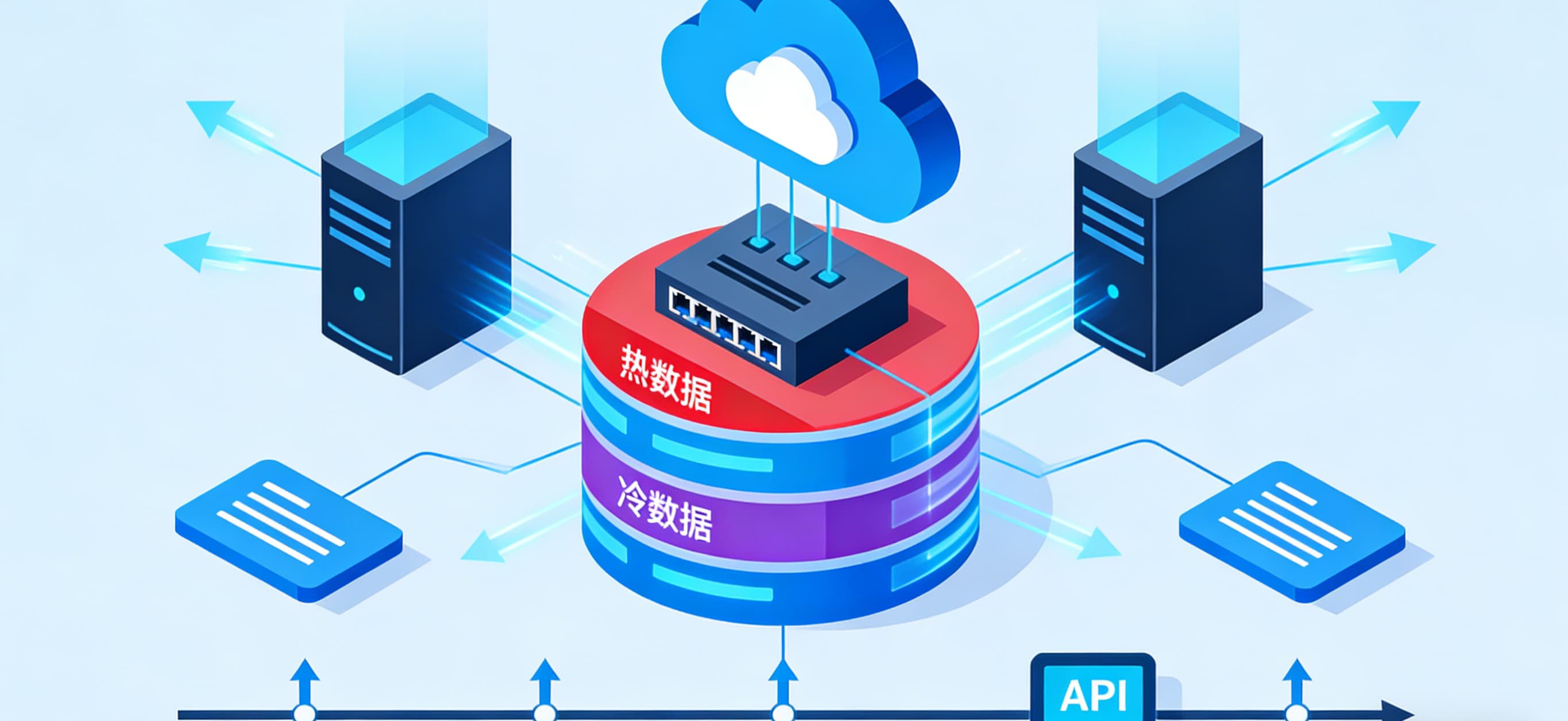
模型权重/政策文件启用OSS服务端加密(SSE-KMS)传输层强制HTTPS+双向证书认证openssl req -x509 -newkey rsa:2048 -nodes -keyout gov_key.pem -out gov_cert.pem -days 365阿里云安全组配置-开放端口:8800(HTTP API), 443(HTTPS)-访问控制:-仅允许政务VPN IP段(如10.123.0.0/16)-启用云盾WAF防御SQL注入-存储加密: model_encrypted = aliyun_oss.encrypt_file(file_path="./baichuan2-13b-4bit-gptq",kms_key_id="alias/gov-model-key" 使用KMS国密加密)审计追踪接入ActionTrail日志服务,记录所有API调用关键词触发告警(如查询"涉密文件"时自动通知审计部门)部署架构图
操作总结:
压缩:使用BitsAndBytesConfig进行4-bit量化部署:通过vLLM+FastAPI搭建高性能API服务安全:OSS+KMS加密 + 政务VPN白名单运维:接入阿里云监控与ActionTrail日志微信阿里云服务器配置
推荐阅读
- 云服务器 入门18英寸巨屏游戏本天花板!售价近40000元的雷蛇灵刃18上手体验 2025-12-22 06:03:57
- 云终端服务器软件下载手机DNS是否需要改?场景判断、设置方法与可靠推荐 2025-12-22 05:53:53
- 辽宁集群服务器云服务器2025年小程序开发咋选?199元起的模板和几万的定制,差别可太大? 2025-12-22 05:43:46
- 阿里云服务器远程界面连不上“网”?我就自己创造了“网络” 2025-12-22 05:33:44
- 云服务器充值ESP8266的五大用途 2025-12-22 05:23:36